ちょっと所要で手書きの数字を認識させたい今日この頃。
参考にさせていただきました。
で、今回手書きの数字データMNISTからmnist.traineddataを作ってみた。
MNISTから画像ファイルの抽出はこちら。
で、Windows10環境にWSL(Windows Subsystem for Linux)でUbuntu環境こさえてやってみた。
# root権限
sudo su -
# Ubuntuを更新
apt update
apt upgrade -y
# Tesseractインストール
add-apt-repository ppa:alex-p/tesseract-ocr -y && apt update
apt install -y tesseract-ocr
# 作業フォルダ作成
mkdir ~/tess
cd ~/tess
# 言語情報を取得
git clone --depth 1 https://github.com/tesseract-ocr/tesseract.git
git clone --depth 1 https://github.com/tesseract-ocr/langdata.git
echo "export TESSDATA_PREFIX=/usr/share/tesseract-ocr/4.00/tessdata/" >> ~/.profile && source ~/.profile
# 末尾に追記あり
wget https://github.com/tesseract-ocr/tessdata/raw/master/jpn.traineddata -P $TESSDATA_PREFIX
wget https://github.com/tesseract-ocr/tessdata_best/raw/master/eng.traineddata -O $TESSDATA_PREFIX/eng_best.traineddata
wget https://github.com/tesseract-ocr/tessdata_best/raw/master/jpn.traineddata -O $TESSDATA_PREFIX/jpn_best.traineddata
wget https://github.com/tesseract-ocr/tessdata_best/raw/master/jpn_vert.traineddata -P $TESSDATA_PREFIX
# 言語情報の確認(6個あるはず)
tesseract --list-langs
# 動作確認(ocr-test.pngは適当に画像を用意すること)
tesseract ~/tess/ocr-test.png stdout
# OCR-Dをダウンロード
cd ~/tess
git clone --depth 1 https://github.com/OCR-D/ocrd-train.git
# Pythonに必要なライブラリをインストール
apt install build-essential libbz2-dev libdb-dev libreadline-dev libffi-dev libgdbm-dev liblzma-dev libncursesw5-dev libsqlite3-dev libssl-dev zlib1g-dev uuid-dev tk-dev
# 公式(https://www.python.org/downloads/)からLinux版Pythonをダウンロードしておく
# /tmp/Python-3.8.3.tarに保存したとして解凍
cd /tmp
tar xzf Python-3.8.3.tgz
# Pythonをインストール
cd Python-3.8.3
./configure -enable-shared
make
make install
sh -c "echo '/usr/local/lib' > /etc/ld.so.conf.d/custom_python3.conf"
ldconfig
# 確認(バージョンが表示されるはず)
python3 -V
# pillowもインストール
apt install -y python3-pip
pip3 install pillow --upgrade pip
# 学習ファイルを配置
cd ~/tess/ocrd-train
mkdir data
# MNISTの画像ファイル(*.tiff)とラベル(*.gt.txt)を fontname-ground-truthフォルダとして ocrd-train/data配下につくる
# ここでは mnist-ground-truthとして配置したとみなす
# traindataを作成
nohup time -f "Run time = %E\n" make training MODEL_NAME=mnist >> train.log 2>&1 &
# 実行結果をモニタ
tail -f train.log
# 実行結果をtessesactの辞書データ置き場にコピー
cp data/mnist.traineddata $TESSDATA_PREFIX/mnist.traineddata
# 動作確認(ocr-test.pngは適当に画像を用意すること)
# この時点では警告『Failed to load any lstm-specific dictionaries for lang mnist!!』が出るが解析はできる
tesseract ~/tess/ocr-test.png stdout -l mnist適当な画像(ocr-test.png)を解析してみたところ、-l jpnを指定したよりは認識率は上がった。
が、まだまだですね。
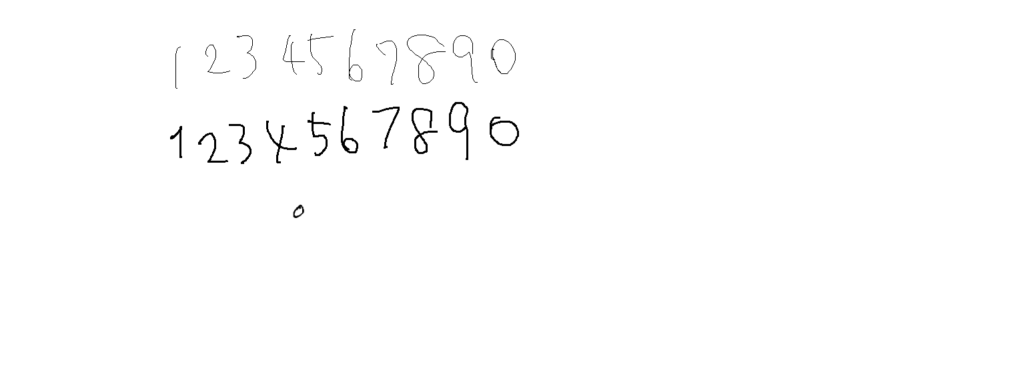
tesseract ~/tess/ocr-test.png stdout -l jpn
[23 代159S40
123V5678o
tesseract ~/tess/ocr-test.png stdout -l mnist
1233458780
1345779make trainingコマンドが20分程度で終わってしまっているのもなー
チューニングしようがあるのか謎い…。
でも手書きの認識なんてこんなものなのかな?
あと『Failed to load any lstm-specific dictionaries for lang mnist!!』警告は一応消すことができました。
こちらの記事の下の方に記載しておきます。
追記(2022′ 8月)
久し振りになぜかWindows11でやり直すハメに。
wget https://github.com/tesseract-ocr…のURLが変わっているぞ?
それっぽいURLで取得したけど、jpn系が動かない。
engは動いたからいっか?
# URLを下記に置き換えてみる
wget https://github.com/tesseract-ocr/tessdata/raw/4.00/jpn.traineddata -P $TESSDATA_PREFIX
# 動作確認
tesseract ~/tess/ocr-test.png stdout -l jpn
Error opening data file /usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory.
Failed loading language 'jpn'
Tesseract couldn't load any languages!
Could not initialize tesseract.
tesseract ~/tess/ocr-test.png stdout -l eng
| 23 &8 b9%40
11$\L5L79q o0と思ったら、Ubuntu22.04.1 LTSで実行してたけど、Ubuntu18.04.5 LTSで同じことしたら動きました…。
tesseract ~/tess/ocr-test.png stdout -l jpn
Warning: Parameter not found: textord_tabfind_vertical_horizontal_mix
Detected 38 diacritics
`①③ JV①⑨
ー2苫纏ぢ傳7悪『〇
⑥解析に難あり?
長いので分ける。
他にもニッチなIT関連要素をまとめていますので、よければ一覧記事もご覧ください。
